山西农业大学农业基因资源研究中心联合中国农业科学院作物科学研究所、华大科技在Scientific Data(JCR Q1区,IF5year=8.9)上发表题为“Telomere-to-telomere genome assembly of sorghum”的文章。该研究成功构建了一个古老高粱地方品种矬护巴子(CHBZ)端粒到端粒(T2T)Gap-Free参考基因组,为后续高粱遗传学、基因组学和进化史研究提供了重要基础。

一、基因组组装与组装质量评估
研究团队利用28.65 Gb PacBio HiFi数据(~40X,N50=16,638 bp)、304.06 Gb Oxford Nanopore超长(~419X,N50=52,442 bp)和304.93 Gb高通量染色体构象捕获(Hi-C)DNBSEQ测序数据(~421X),123.3 Gb转录组数据,成功构建高粱(CHBZ)端粒到端粒(T2T)Gap-Free参考基因组。
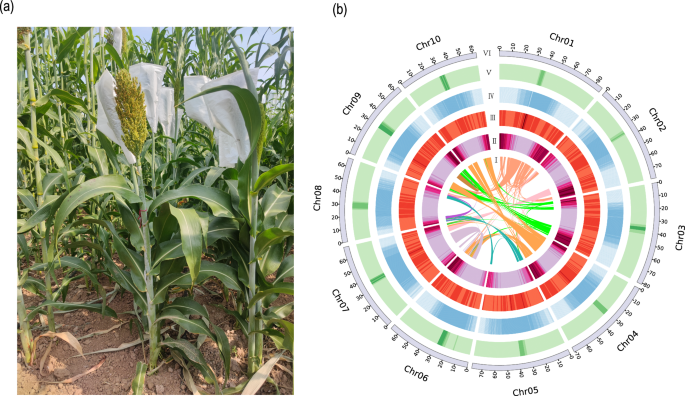
图1 (a) CHBZ植物照片
(b) CHBZ基因组的基因组Circos图
组装得到的CHBZ基因组大小约为724.85 Mb,Contig N50=71.06 Mb,包含10条染色体,成功识别10个着丝粒和20个端粒,端粒重复次数明显高于BTx623基因组。且在完整性方面表现出较高质量:BUSCO评分99.01%,k-mer完整性:98.88%,QV:61.60,LTR组装指数(LAI)值:23.63。

图2 CHBZ基因组组装质量评估
(a)端粒、着丝粒检测图
(b) CHBZ和BTx623基因组中端粒重复次数统计(c) Hi-C互作热图(d) BUSCO评估
二、基因组注释
该研究使用RepeatModeler(v1.0.4)识别de novo重复序列,使用LTR-FINDER(v1.0.7)注释长末端重复序列,随后使用RepeatMasker(v4.0.7),RepeatProteinMasker(v4.0.7)识别DNA和蛋白质转座因子(TE)。利用TandemRepeatFinder(v4.10.0)进行串联重复序列分析,共获得510.36 Mb(~70.41%)重复序列。
研究团队采用基于转录组预测、同源比对预测、从头预测的方法进行基因预测和功能注释,共鉴定到32,855个蛋白质编码基因。其中,32,746个基因(99.67%)在至少一个功能数据库中进行了注释。注释结果与玉米(T2T Mo17)、水稻(T2T-NIP)、高粱BTx623进行外显子长度、内含子长度频率检测,检测结果显示一致性较高。此外,25,873个基因(78.75%)在15个RNA测序数据集中表现出可检测的转录活性(FPKM≥1)。且预测蛋白质的完整BUSCO评分约为99.38%,表明基因注释表现出了较高的准确性与完整性。

图3蛋白质编码基因质量评估
三、比较基因组分析
此外,为进一步确定CHBZ和BTx623(GCF_000003195.3)基因组之间的同源关系,使用JCVI(v1.1.18)检测CHBZ和BTx623基因对之间的同源区块。分析结果产生24,685个直系同源对:CHBZ中有24,639个(74.6%),BTx623中有24,637个(72.2%)。与BTx623基因组相比,已鉴定出161个CHBZ特异性存在/缺失变异基因(PAVs),并且其中129个基因至少在一个RNA-Seq样本中表达。

图4 CHBZ和BTx623之间的同源关系和PAV
高粱CHBZ高质量T2T Gap-Free完整基因组的完成,为揭示CHBZ重要农艺性状形成提供了坚实的基础,并且为高粱及其他C4作物遗传研究和育种提供了重要参考。
山西农业大学农业基因资源研究中心李萌、王海岗、秦慧彬、侯森,华大科技陈春海等为论文共同第一作者,山西农业大学农业基因资源研究中心穆志新、中国农业科学院作物科学研究所刘敏轩、华大科技高鹏为论文共同通讯作者。该研究得到山西省农业种质资源保护与利用项目和山西省基础研究计划项目资助。



